冯诺依曼模型改进
冯诺依曼模型
核心:存储程序、顺序执行
特点:
- 数据和指令一律用二进制数表示
- 指令和数据不加区别的混合存储在同一个存储器中
- 顺序执行程序的每一条指令
- 计算机硬件由运算器、控制器、存储器、输入设备、输出设备五大部分组成
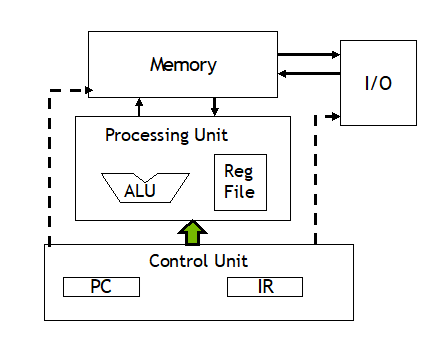
局限性:主存和CPU的分离通常被称为冯诺依曼瓶颈
三个改进
- 缓存
- 虚拟内存
- 低级并行性
缓存
基本知识
缓存:存储位置的集合,可以比其他一些内存位置在更短的时间内访问
CPU缓存:CPU可以以比访问主存更快的速度访问内存位置的集合
CPU缓存可以与CPU同芯片,也可以位于访问速度比普通芯片快得多的单独芯片上
哪些数据或指令存储在cache中
程序倾向于使用物理上接近最近使用的数据和指令的数据和指令
局部性原理
CPU访问存储器时,无论是存取指令还是存取数据,所访问的存储单元都趋于聚集在一个较小的连续区域中
缓存一致性
写直达
当数据被写入缓存时,利用缓存更新主存的数据
写回
标记缓存中更改的数据为脏,当标记为脏的缓存要被替换时,将缓存中标记为脏的行写回主存
缓存映射
全相联映射
可以在缓存的任意位置放置数据
直接映射
每个数据都有自己独特的位置
组相连映射
每个数据可以放置在n个不同位置之一
当冲突时的置换方案:最近使用最少,缓存具有使用块的相对顺序的记录
对cache命中率的间接控制

假设:
最大值为4
当循环开始,A中的元素都不在缓存
一个缓存行包含了A中的四个元素
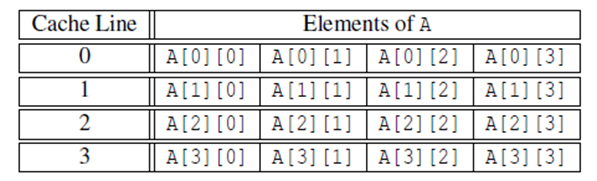
缓存是直接映射的,只能存储A中的8个元素,也即两个cache行
结论:
- 在以上假设下,第一个循环产生四次cache缺失
- 而第二次循环产生了16次cache缺失,每次访问A中元素都缺失了
虚拟内存
使主内存功能成为辅助存储的缓存,利用空间局部性和时间局部性,只将程序的活跃部分保留在主存中
指令级并行
指令级并行(ILP)试图通过让多个处理器组件或功能单元同时执行指令来提高处理器性能
流水线
功能单元分阶段排列
一般来说,具有k个阶段的流水线不会得到k倍的性能改进
- 各职能单位所需时间不同
- 延迟可能导致流水线暂停
多事务
多事务处理器复制功能单元,并尝试同时在程序中执行不同的指令
静态多事务:功能单元在编译时调派
动态多事务:功能单元在运行时调派
为了使用多事务,系统需要找到可以同时执行的指令
- 采用猜测执行,如果预测行为不正确,那么就返回并重新执行任务
其他方法
线程级并行,比ILP粗粒度的并行
能多重读取的硬件
细粒度:处理器在每个指令执行完成后在线程之间切换,跳过停顿的线程
优点:能避免因停顿而浪费的处理器性能
缺点:准备执行一长串指令的线程可能必须要等所有指令执行完
粗粒度:只切换停顿的线程,等待耗时操作的完成
优点:不需要频繁的切换线程
缺点:处理器可能在较短的停顿上闲置,线程切换也可能会导致延迟
硬件并行
Flynn的分类法
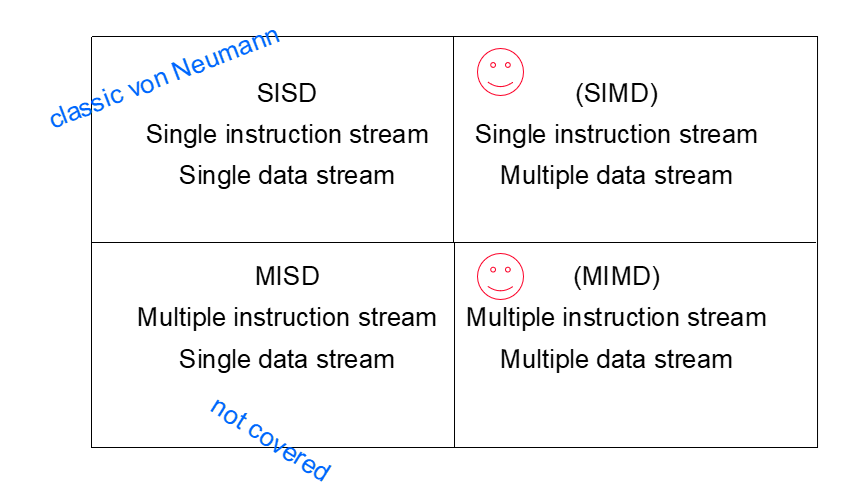
SISD
- 一次执行一条指令、一次读取或存储 一项数据
- 经典的冯诺依曼模型机
- 从逻辑上讲,是单处理器
MISD
- 多个指令流单个数据流
- 并未使用
- 也许适用于流水线计算
SIMD
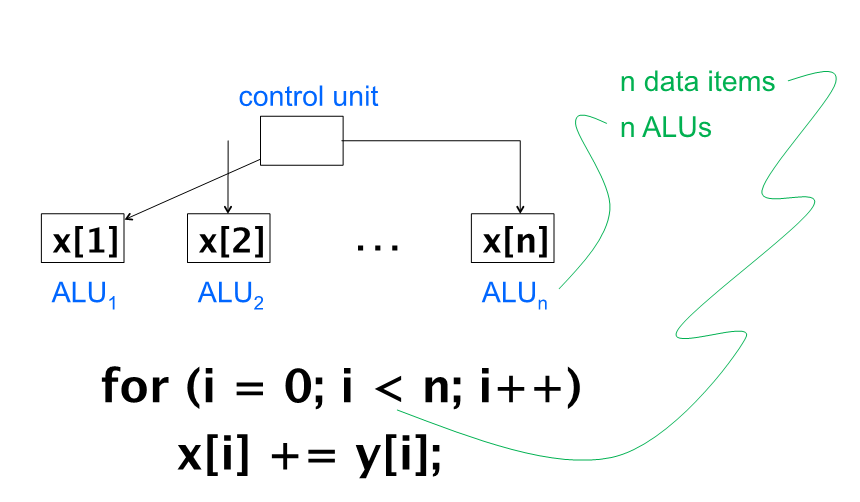
对于单个指令流应用多个数据流
单个控制单元和多个运算单元(ALU)
多处理器执行相同的指令
在经典的SIMD系统中,每个ALU必须等待下一条指令广播才能继续
所有ALU执行相同的指令或者处于闲置状态通过在处理器之间划分数据实现并行,每个处理器看到的数据可能不一样
矢量处理器
对数组或向量进行操作,传统的CPU都是对单个元素或者标量操作
最近的典型系统有以下特征:
- 矢量寄存器
- 矢量化和流水线化的功能单元
- 矢量指令
- 交错内存
- 跨越式的内存访问和硬件分发/收集
优点:
- 快速、易于使用
- 矢量编译器善于识别可矢量化的代码
- 编译器可以提供循环无法矢量化的信息以及原因,帮助用户重新评估代码
- 高内存带宽
- 每个加载的数据项都被使用
缺点:
- 不处理不规则的数据结构以及其他并行架构
- 处理大问题的能力有限制(可扩展性)
MIMD
- 支持在多个数据流上运行多个同步的指令流
- 通常由完全独立的处理单元或处理器组成,每个单元都有自己的控制单元和ALU
- MIMD系统通常是异步的
- 许多MIMD系统都有单独的时钟
- 示例:共享内存和分布式内存机器
MIMD的物理组织
- 共享缓存架构
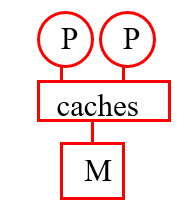
CMP(或同时多线程)
暗示了是共享内存硬件
UMA(统一内存访问)共享内存
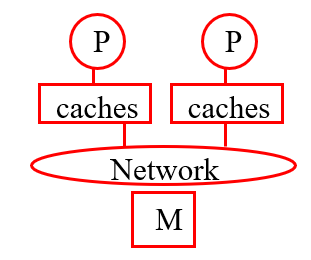
互连网络:总线、多级、交叉等
暗示了是共享内存硬
NUMA(非统一内存访问)共享内存
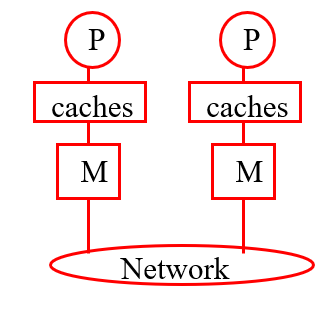
互联网络:交叉、网格、超立方体等
分布式共享内存
分布式系统/内存
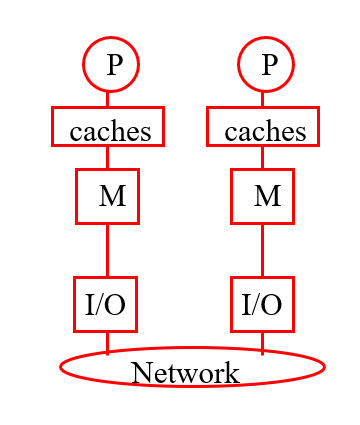
也称为集群、网络
不要将其与分布式共享内存混淆
共享内存系统和分布式内存系统
共享内存系统
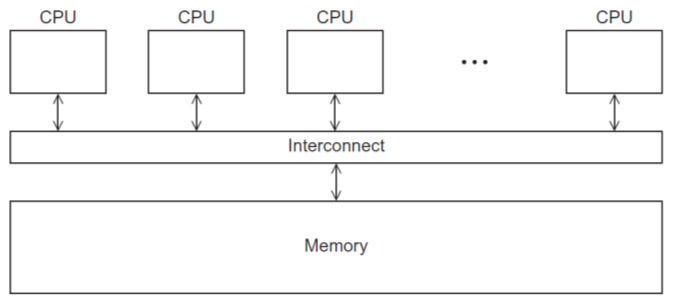
- 通过互连网络连接到内存系统,将一系列自动处理器连接起来
- 处理器可以直接访问系统中的所有数据
- 处理器通常通过访问共享数据结构来进行隐式通信
- 多核处理器在单个芯片上有多个CPU或内核
- 在具有多个多核的共享内存系统中,互连可以将所有处理器直接连接到主内存(UMA),或者每个处理器可以直接连接到主内存块,处理器可以通过内置处理器的特殊硬件访问主存中的其他块(NUMA)
- UMA(统一内存访问)
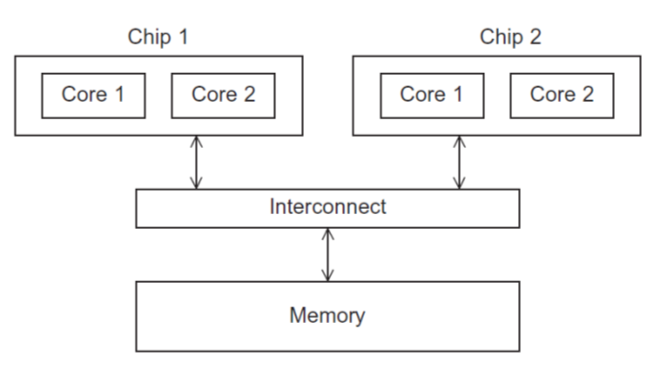 访问所有内存位置的时间对于所有内核都是一样的
访问所有内存位置的时间对于所有内核都是一样的 - NUMA(非统一内存访问)
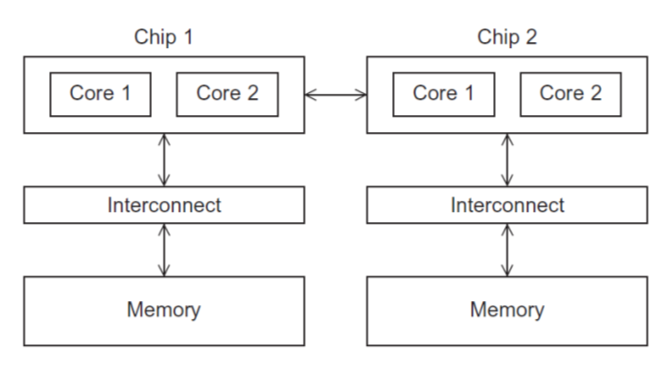 与必须通过其他芯片访问的内存位置相比,可以更快的访问内核位置
与必须通过其他芯片访问的内存位置相比,可以更快的访问内核位置
分布式内存系统
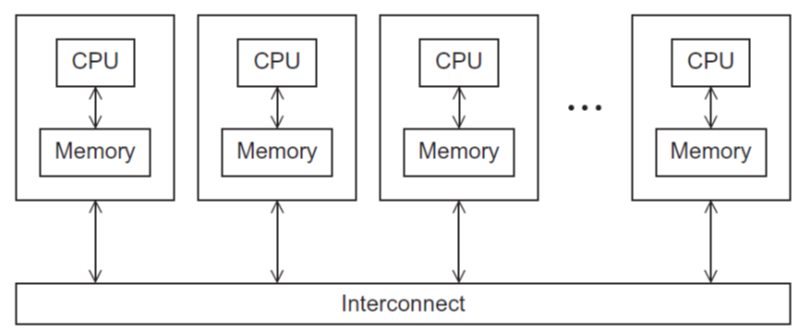
- 每个处理器都有自己的私人内存
- 处理器通过显式的消息传递或特殊功能共享数据
互连网络
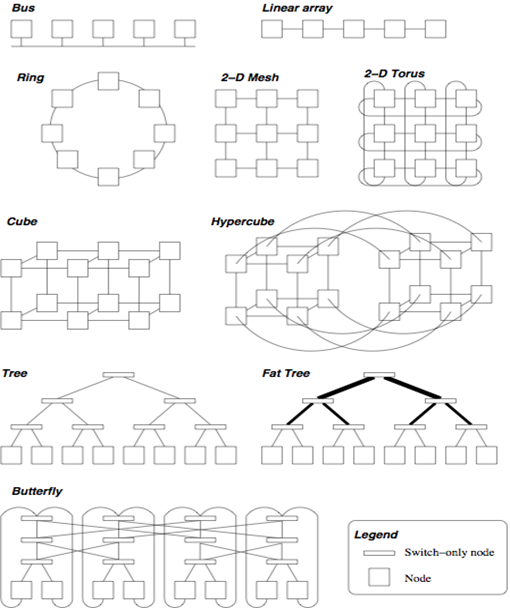
影响分布式和共享内存系统的性能
两类:
- 共享内存互连
- 分布式内存互连
共享内存互连
总线互连
一组并行通信线以及一些控制总线访问的硬件
通信线由连接到它的设备共享
低成本和灵活性
随着连接到总线的设备的数量的增加,对总线使用的争夺也增加,性能下降交换互连
使用交换机控制连接设备中的数据路由
交叉:- 允许不同设备之间同时通信
- 比总线快
- 交换机和连接的成本相对较高
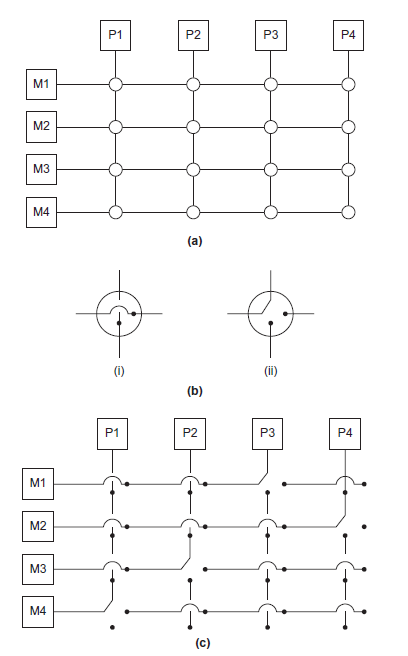
(a)连接4个处理器(pi)和4个内存模块(mj)的交叉开关
(b)交叉结点的内部开关配置
(c)处理器同时访问内存
分布式内存互连
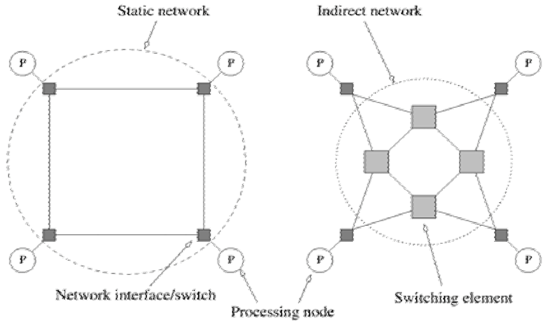
直接互联(静态网络)
每个开关都直接连接到处理器-内存对并且开关相互连接
它由处理节点之间的点对点通信链接组成间接互连(动态网络)
交换机可能无法直接连接到处理器
它使用交换机和通信链接构建
度量的指标
对分宽度
衡量“同时通信次数”或“连接性”的度量
对分宽度给出了“同时通信次数”的“最坏情况估计”
计算对分宽度的另一种方法是删除链接将节点分成两个相等的两半所需的最小链接数,删除的链接数就是对分宽度带宽
链接传输数据的速度
对分带宽
衡量网络质量的指标
不是计算一半网络的链接数量,而是将它们的带宽相加延迟
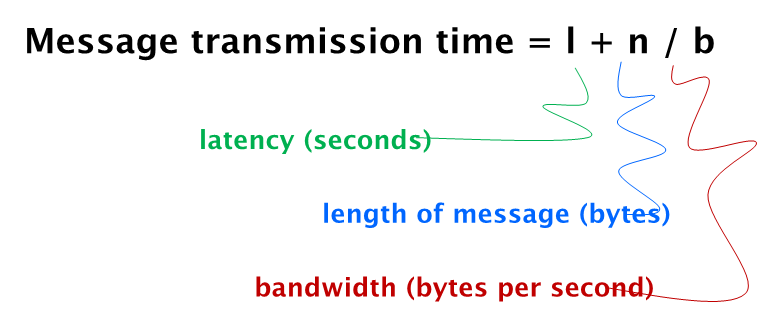
源开始发送数据到目的节点接收到第一个bit之间的时间间隔
信息传送时间
完全连接的网络
每个交换机都直接连接到其他交换机
这是一个“理论上最好的互连”,但不切合实际
线性网络
线性排列
将交换机排列成一维网格
对应于二维网格的行和列环
允许在末端开关之间进行环绕的变种
本质上支持双向流水线
多维网格网络
网格
将线性阵列泛化为2D或3D
仅允许相邻交换机之间的通信环
变种,包括网格边缘交换机之间的环绕连接(网状环绕)
超立方体
超立方体是一个多维网格,每个维度上正好有两个处理器
d维度的超立方体具有p=2^d^ 节点
构建
一维超立方体是一个具有两个处理器的完全连接系统
二维超立方体由两个一维超立方体加入“相应”的开关构建
三维超立方体由二维超立方体构建
d维超立方体由d-1维超立方体构建
每个处理器都与其他处理器连接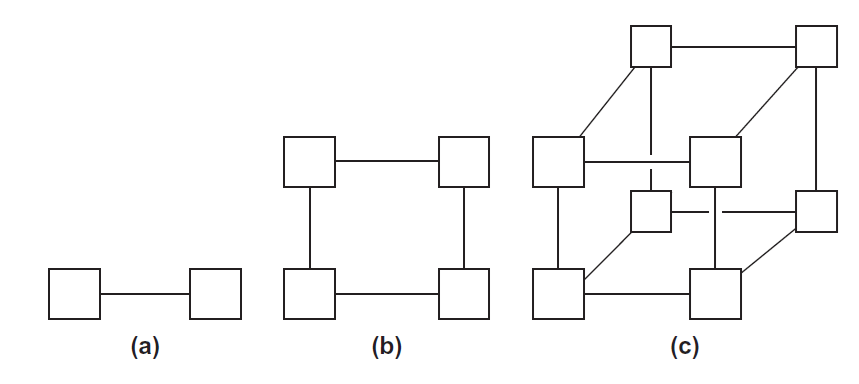
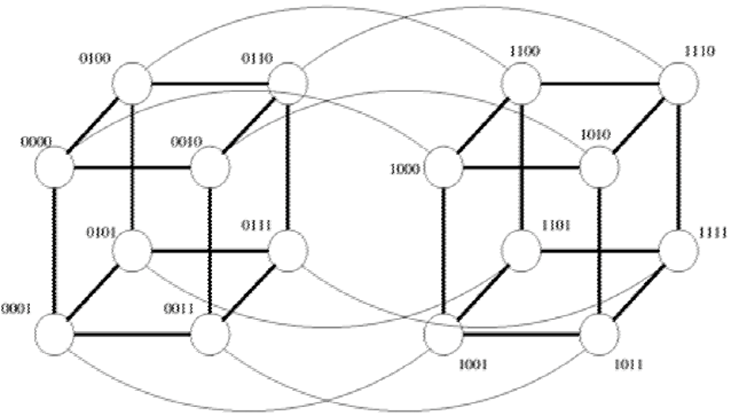
超立方体的编号方案
如果有p/2节点的子立方体的编号,则通过用“0”或“1”加在其中一个子立方体编号中来获得p节点编号方案
这种方案可以通过不同位数的个数来判断两个节点是否是相邻的(有两位及以上就是分开的)
间接互连
eg:crossbar、fat tree
通常显示单向链接和处理器集合,每个处理器都有一个传出和传入的链接,以及一个交换网络
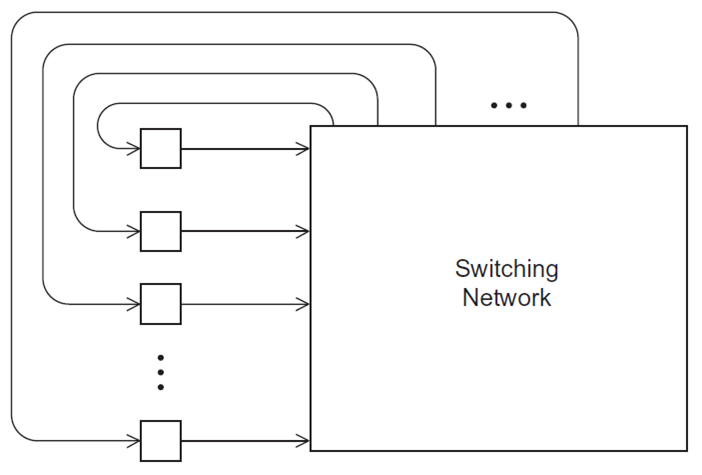
分布式内存的交叉互连
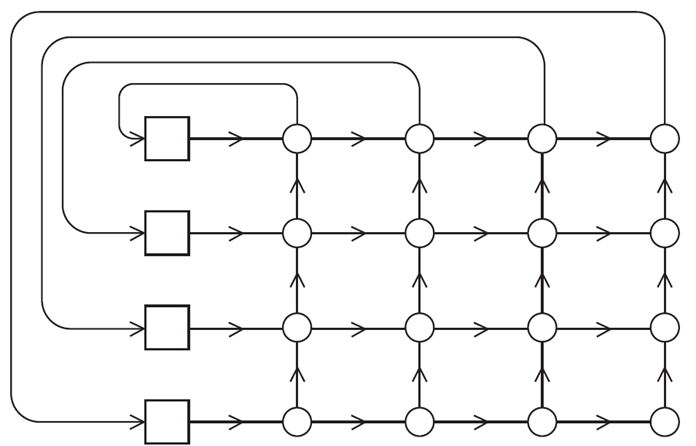
蝴蝶网络
间接拓扑
n=2^d^ 处理器连接的节点由nlog(n+1)交换机节点连接
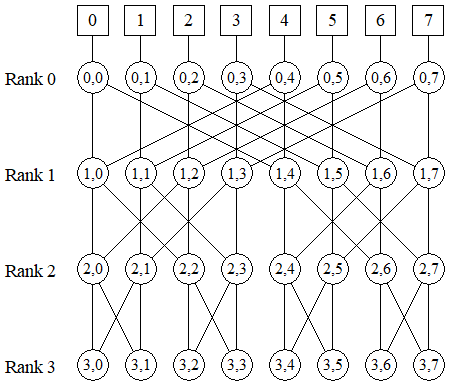
路由:
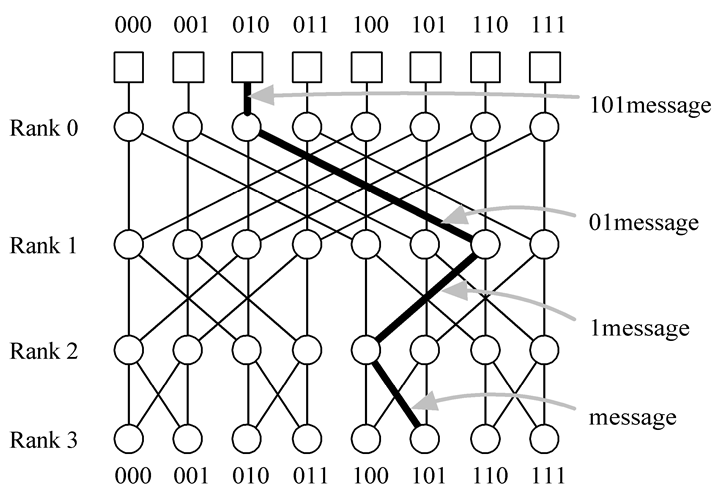
树状网络
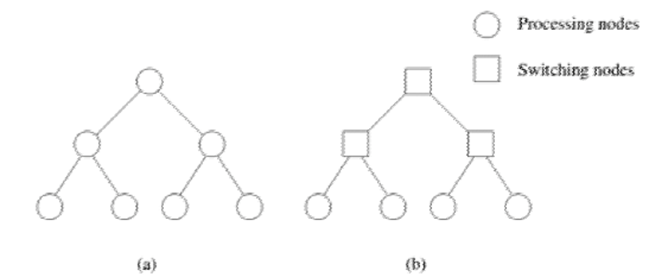
树状网络是任意两个节点之间只有一条路径的网络
静态树状网络在树的每个节点都有一个处理元件
动态树状网络中中间节点是交换节点,叶子节点是处理节点
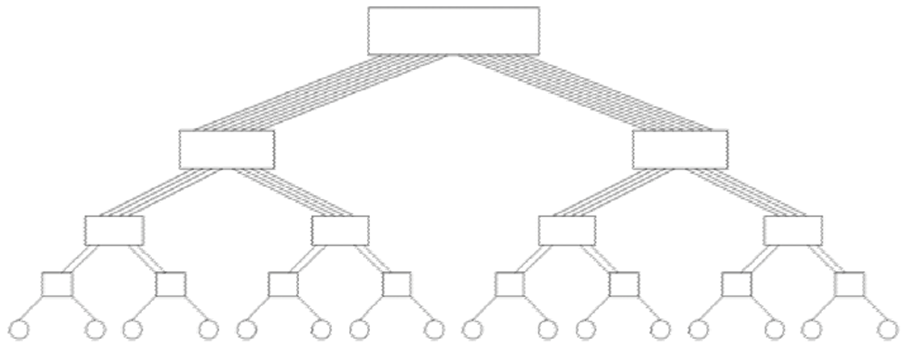
路由时树的高级别上存在通信瓶颈,解决方法Fat Tree Network
内存层次和缓存一致性
内存层次
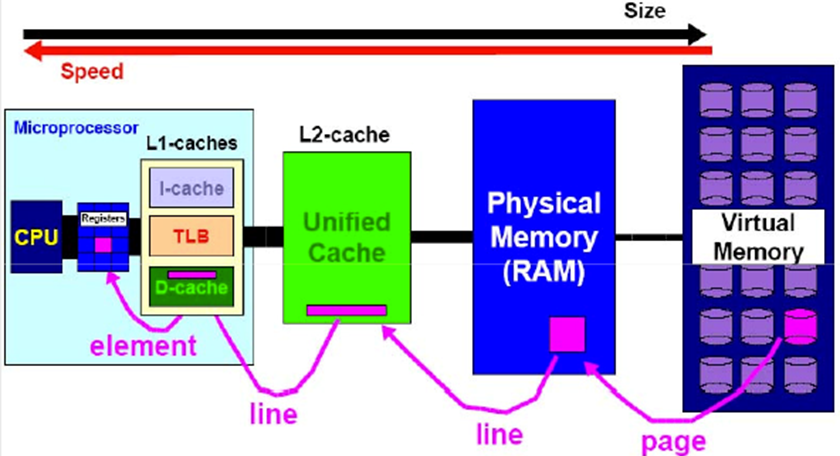
内存延迟
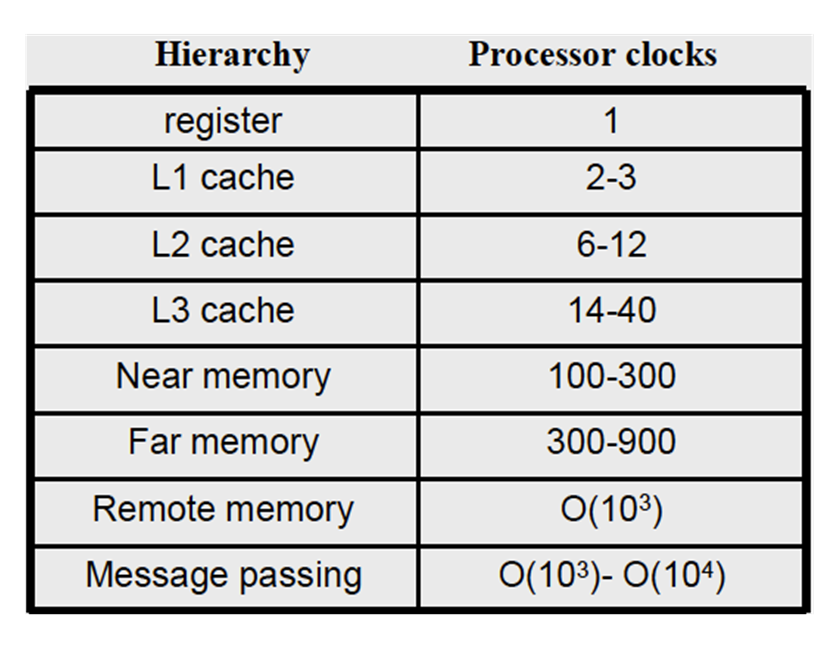
缓存一致性
- 共享内存的一个重要问题
- 处理器可能会缓存相同的位置
- 如果一个处理器写该位置,所以其他处理器都最终必须看到这个写入
为了解决这个问题,有如下解决方案:
无效或更新
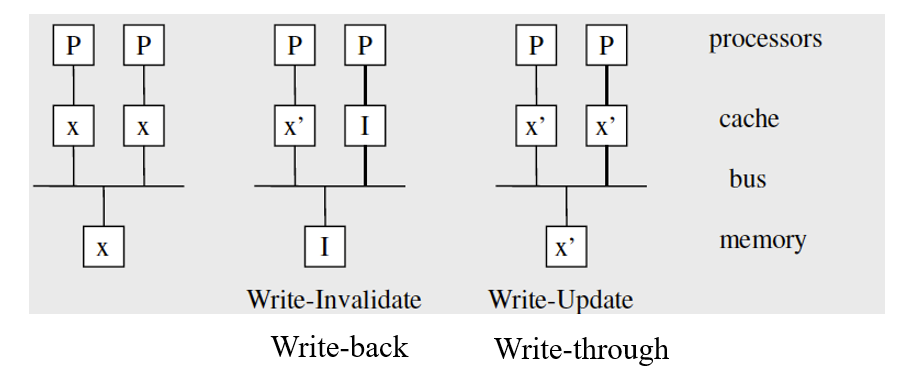
write-through(写直达):当数据写入缓存的时候也写入主存
write-back:数据不会立即写入,缓存中数据标记为脏,当缓存行被内存中新的缓存行替代时,标记为脏的数据会被写入内存
比较:
- 写无效:当处理器写数据给其本地缓存时,其他缓存的副本必须无效。
如果写直达,它也更新了内存中的副本。
如果写回,则会使内存中的副本失效。
当一个生产者生产数据,多个消费者消费数据时不利 - 写更新:当处理器写数据给其本地缓存时,必须立即更新其他缓存的副本。
如果写直达,它也更新了内存中的副本。
如果写回,数据不会立即写入。缓存中更新的数据标记为脏,当缓存行被内存中的新缓存行替换时,脏数据会写入内存。
当一个CPU读取数据之前一个CPU多次进行写操作或缓存被不再读取的数据填满时不利
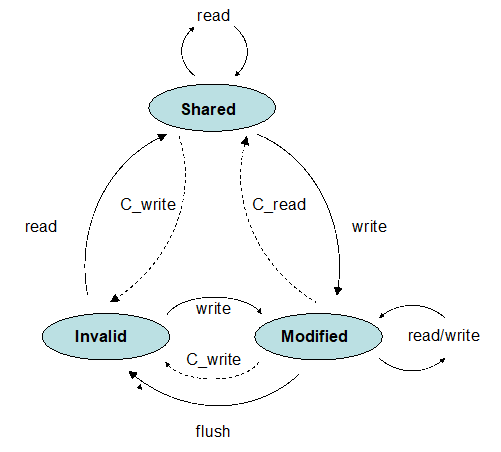
MSI协议
现代的机器默认使用写无效协议,状态:shared、invalid、modified
shared:数据项的多个有效副本(写需要变成modified,并且产生invalid)
modified:仅存在一个副本(写不改变状态)
invalid:数据副本无效的(读产生数据请求并且更新状态为shared)
注:这组状态转换不是独一无二的,也有MESI(E表示exclusive(独占的))
简单的MSI一致性协议状态转换图(实线表示处理器操作、虚线表示一致性操作(总线监听动作))
监听cache一致性:
- 核心共享一个总线(不是必须的,但支持广播)
- 总线上传输的任何信号都可以被连接到总线上的所有核心“看到”
- 当核心0更新存储在其缓存中的x副本时,它也会在总线上广播该信息。
- 如果核心1正在“监听”总线,它将看到x已经被更新,它可以将x的副本标记为无效。
如何将无效发送给正确的处理器:
- 广播所有无效和读请求
- 监听cache监听并且在本地做出适当的一致性操作
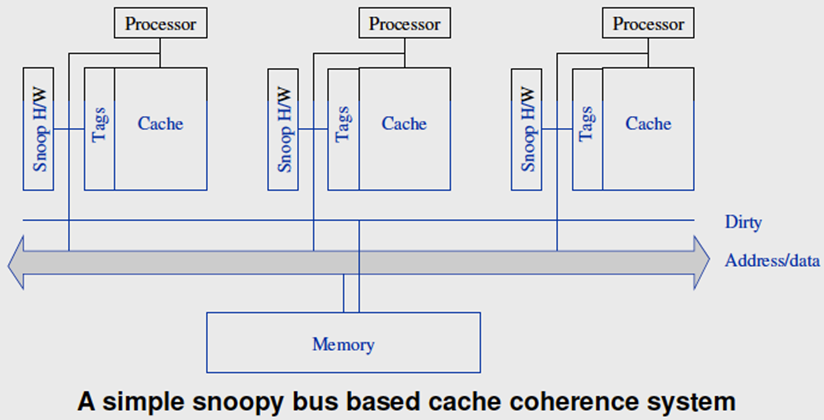
监听cache的操作:
- 一旦数据被标记为dirty(modified),那么所有的后续操作都可以在本地的缓存中执行,无需外部传输
- 如果一个数据项被多个处理器读取,在所有缓存中转换到共享状态,所有随后的读操作都变为本地操作
- 但是,如果多个处理器读取和更新相同的数据,就会出现一个基本的瓶颈问题,在总线上生成一致性请求,总线受带宽限制,每秒更新次数受到限制
- 如果是写直达Cache,不需要额外的互联网络,因为每个核都能检测写;如果是写回Cache,需要额外的通信,因为对Cache的更新不会立即发送给内存。
一致性花费:
- 监听Cache:每个一致性的操作都要被发送给所有的处理器。
- 为什么不将一致性请求只发送给那些需要被通知的处理器呢?(于是产生了基于目录的Cache一致性监听协议)
基于目录的cache一致性协议
基于目录:共享状态保存在目录中
存在位:表示缓存块和缓存它们的处理器的位图
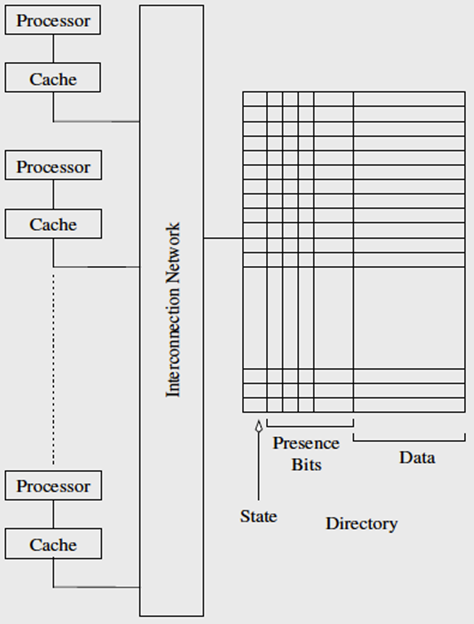
示例:
x=1;
| P0 | P1 | |
|---|---|---|
| Time 0 | load x | load x |
| Time 1 | write #3 |
当处理器P0和P1访问变量x 对应的块时,会发生什么
当处理器 P0 和 P1 访问与变量 x 相对应的块时,块的状态更改为共享,并更新了存在位以指示处理器 P0 和 P1 共享块。
当P0写入变量时,会发生什么?
当 P0 在变量上执行存储时,目录中的状态更改为脏,P1 的存在位被重置。在处理器 P0 上执行的此变量的所有后续操作都可以在本地进行。
如果另一个处理器读取该值,将会发生什么?
如果其他处理器读取了该值,目录会注意到脏标签,并使用存在位将请求直接指向相应的处理器。处理器 P0 更新内存中的块,并将其发送到请求处理器。存在位将进行修改以反映此情况,状态更新为共享。
性能:
- 开销 : 状态更新的传播 ( 通信开销 ) ; 从目录生成状态信息 ( 争用 )
- 如果一个并行程序需要大量的一致性操作(大量的读写共享数据块),目录最终会限制它的并行性能
- 存储目录的位可能会增加很大的开销-考虑扩展到许多处理器
- 目录成为一个争论点—分布式目录方案是必要的
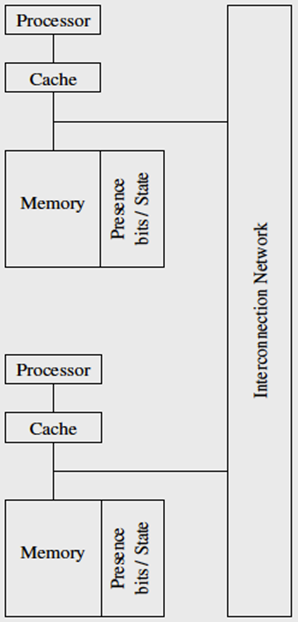
分布式目录:
- 分布式目录方案的性能:比监听系统或集中式目录系统更具可扩展性
- 允许O(p)处理器同时进行一致性运算
- 底层网络必须承载所有一致性请求
- 网络的延迟和带宽成为根本的性能瓶颈
伪共享
伪共享指的是不同处理器更新同一缓存线的不同部分的情况。
CPU缓存在缓存行而不是单个变量上运行。
串行版本:
1 | int i,j,m,n; |
并行版本:
1 | /*private varibles*/ |
假设:共享内存系统有2个核,m = 8,y [0]存储在高速缓存行的开头,并且高速缓存行可以存储8个双精度数,而y占用一个完整的高速缓存行。
问:当核心0和核心1同时执行其代码时会发生什么?
答:因为y的所有值都存储在单个高速缓冲行中,所有每次一个核执行语句y[i]=f(i,j),高速缓存行就会失效,当另一个核尝试执行该语句的时候由于自己的状态为invalid,就必须从内存中将更新过的高速缓存行取出。尽管核0和核1不会访问对方的元素,但大量的赋值操作会访问主存,这就是伪共享。
总结:
- 伪的共享不会导致错误的结果。
- 他能引起过多不必要的访存,降低程序的性能。
软件并行
SPMD——单程序多数据
SPMD 程序由单个可执行程序组成,通过使用有条件分支,可以表现得像是多个不同的程序。

SPMD可以实现数据并行

编写并行程序
1 | double x[n], y[n]; |
假如有p个进程,可以让进程0负责0,……,n/p-1的相加,进程1负责n/p….2n/p-1的相加,以此类推。
将工作划分为多个进程/线程
每个进程/线程获得的工作量大致相同
通信被最小化
安排进程/线程同步
安排进程/线程通信
共享内存
动态线程
主线程等待工作,派生新线程,并在线程完成后终止。
有效利用资源,但是创建和终止线程非常耗时。
静态线程
创建并分配工作的线程池,但是直到清理后才终止。
更好的性能,但可能浪费系统资源。
不确定性
如果给定的输入可以导致不同的输出,则计算是不确定的,例如:
1 | …… |
假设线程1中的值为19,线程0的值为7,最后的输出有两种情况:
情况1:
线程1> my_val = 19
线程0> my_val = 7情况2:
线程0> my_val = 7
线程1> my_val = 19
然后执行以下代码:
1 | my_val = Compute_val(my_rank); |
假设x为共享内存中的值初始化为0,那么调用之后我们所期望的结果为19+7+0=28。
但是我们如果按照下述顺序进行执行:
| time | core 0 | core 1 |
|---|---|---|
| 0 | 完成对my_value的赋值 | 调用compute_val |
| 1 | 把x=0加载到寄存器 | 完成对my_value的赋值 |
| 2 | 把my_value=7加载到寄存器 | 把x=0加载到寄存器 |
| 3 | my_value与x相加 | 把my_value=19加载到寄存器 |
| 4 | 存储x=7 | my_vlaue与x相加 |
| 5 | 开始其他工作 | 存储x=19 |
按照如此顺序,x最后的值为19,不同的执行顺序,可能导致不同的结果
解决方案:
- 竞争条件
- 临界区
- 互斥
- 互斥锁定
我们可以更改上面的代码如下:
1 | my_val = Compute_val(my_rank); |
使用互斥量增加了串行性,可以有代替互斥量的方法:
在忙等待时:
1 | ok_for_1=false; |
分布式内存
消息传递的方式:API至少提供一个发送函数和一个接受函数。
1 | char message [ 1 0 0 ] ; |
程序段为SPMD,变量消息引用不同进程上的不同内存块。
单向通信
- 在单向通信或远程内存访问中,单个进程将调用一个函数。
- 这样可以简化沟通。 它可以大大降低通信成本。
- 这些优点中的某些优点在实践中可能难以实现。
划分全局地址空间的语言
允许用户使用某些共享内存技术对分布式内存硬件进行编程。
考虑下面的共享内存向量加法的伪代码
1
2
3
4
5
6
7
8
9shared int n = . . . ;
shared double x [ n ] , y [ n ] ;
private int i , my_first_element , my_last_element ;
my_first_element = . . . ;
my_last_element = . . . ;
/ * Initialize x and y */
. . .
for ( i = my_first_element ; i <= my_last_element ; i++)
x [ i ] += y [ i ] ;首先定义两个共享数组,x和y。如果分配的核同时拥有x和y的元素,那么执行速度是很快的,但是如果核分配的全为x或者y,那么程序的性能非常糟糕,因为每次都要访问自己远端的内存。
私有变量被分配到执行进程的核心的局部内存中,共享数据结构中的数据分布由程序员控制。
输入和输出
当我们的并行程序需要执行I / O时,请进行以下假设并遵循以下规则:
- 在分布式内存程序中,只有进程0会访问stdin。在共享内存程序中,只有主线程或线程0将访问stdin。
- 在分布式内存和共享内存程序中,所有进程/线程都可以访问stdout和stderr。
- 但是,由于输出到stdout的顺序不确定,在大多数情况下,除了调试输出之外,所有输出到stdout的只有一个进程/线程。
- 调试输出应该始终包括生成输出的进程/线程的级别或id。
- 只有单个进程/线程将尝试访问除stdin、stdout或stderr之外的任何单个文件。例如,每个进程/线程可以打开自己的私有文件进行读写,但没有两个进程/线程会打开相同的文件。