流水线的基本概念
1. 什么是流水线
定义:流水线是利用执行指令操作之间的并行性,实现多条指令重叠执行的技术
1.1 术语
流水段(流水级):完成一条指令的一部分操作
机器周期(流水线周期):指令沿流水线移动一个流水段的时间。长度取决于最慢的流水段,一般是一个时钟周期(有时是两个时钟周期)。每个流水线周期从指令流水线流出一条指令
吞吐量:单位时间从流水线流出的指令数
流水线设计者:平衡每个流水段的时间,使之等长。因此,每条指令在流水线的平均执行时间在理想情况下为:非流水线机器平均指令执行时间/流水线机器段数
流水线加速比:非流水线机器平均指令执行时间/流水线机器平均指令执行时间
理想情况:流水线加速比=流水线机器段数
1.2 特点
- 类似自动装配线
- 有多个段(级),段间有流水线寄存器
- 每个流水段执行指令或操作的不同部分
- 流水段之间采用同步时钟控制
- 流水线是开发串行指令流中并行性的一种实现技术
2. RISC指令系统的特点
- 所有参加运算的数据来自寄存器,结果也写入寄存器,寄存器为32/64位
- 访存只有
load和store指令 - 指令的类型较少,所有指令长度相同
- 不同指令执行的时钟周期数差别不大
3. 非流水线方式下RISC指令系统的实现
3.1 多周期CPU实现
假定指令系统是MIPS的一个定点子集:load/store指令,ALU指令,转移指令
一条指令的执行过程最多需要5个时钟周期:CPI=5
图示:

电路图示:
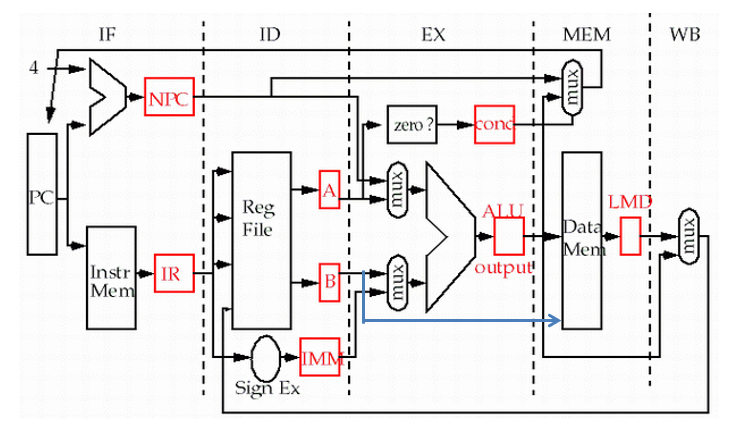
上图分析:
IF:Instruction fetch cycle
- 按照PC内容访问指令存储器,取出指令
- PC+4→NPC,以获取下一条指令地址
ID:Instruction decode/register fetch cycle
- 指令译码
- 读寄存器
- 如果需要,则符号扩展指令中的位移量
EX:Execution(执行)/effective address cycle
- Load/Store:计算数据存储器有效地址
- R-R/R-I ALU:执行运算操作
- Branch:做“=0?”测试,并置条件,计算目标地址
MEM:Memory access
- Load:送有效地址到数据存储器,取数据
- Store:写ID,读出数据到有效地址单元中
- Branch:如果条件满足计算目标地址送PC;否则NPC送PC
WB:Write-back cycle
- Load or ALU:写结果到寄存器堆
3.2 多周期实现的改进
- 对于Branch,将“=0?”测试和计算可能的转移目标地址提前到ID
- 完成ALU指令在MEM cycle
图示:
改进硬件冗余
- ALU可以共享
- 数据和指令存储器可以合并
4. 经典5段流水线RISC处理器
4.1 特点
- 5个段构成一个指令流水线,一条指令经过每个段
- CPI减小到1,因为平均每个时钟周期发射或完成一条指令
- 在任意时钟周期,在每个流水段正执行一条指令的部分
- 理想情况下,性能提升5倍
图示:

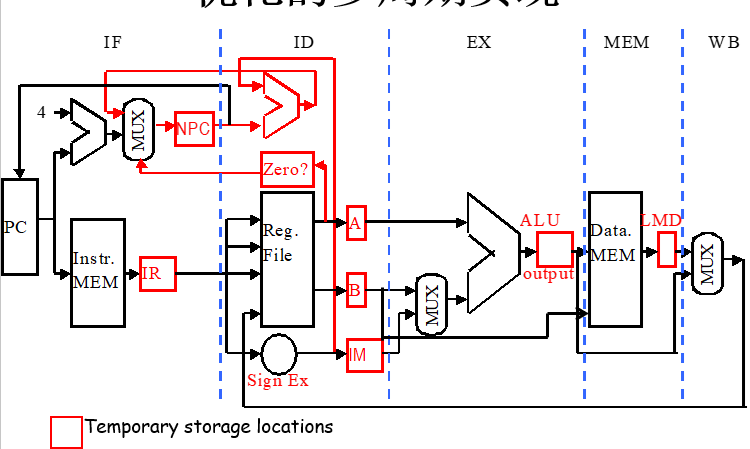
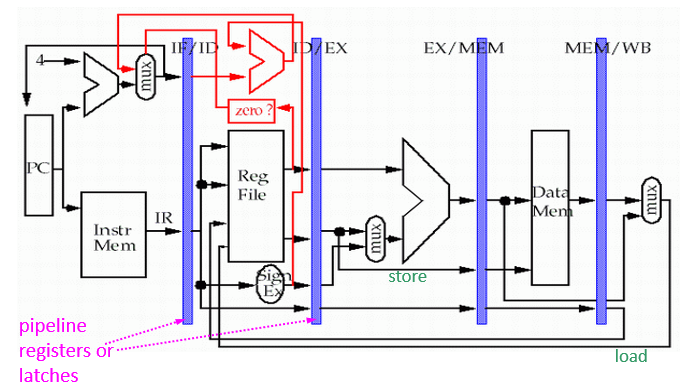
4.2 实现
为了实现,在每两段之间新增流水线寄存器,其作用:
- 在本周期提供流水段中指令操作的数据及控制信息
- 周期结束时,存指令操作结果供下一个流水段指令使用
如下图蓝色部分:
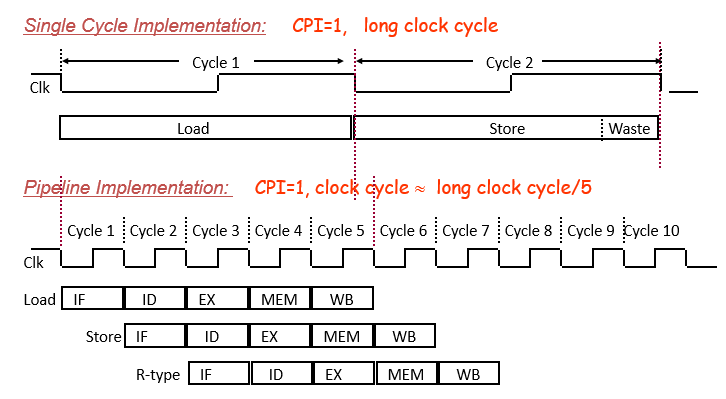
4.3 对比
对比单周期实现,流水线减少了时钟周期长度
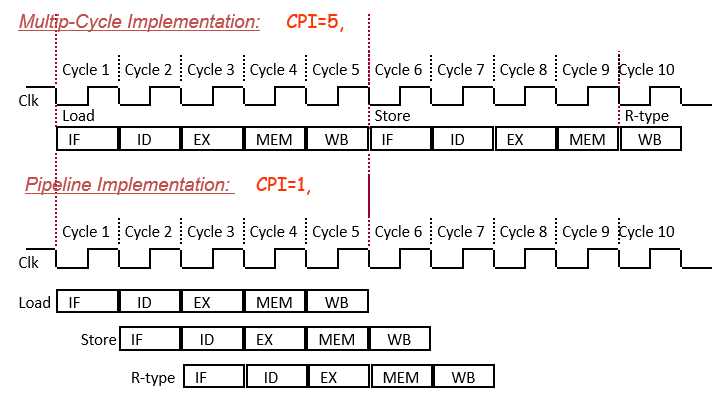
对比多周期实现,流水线减少了CPI
4.4 问题
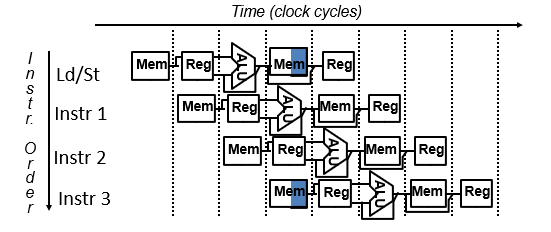
4.4.1 存储器访问冲突
结构冒险(structure hazard):在同一时钟周期不同操作使用同一数据通路资源
图示:
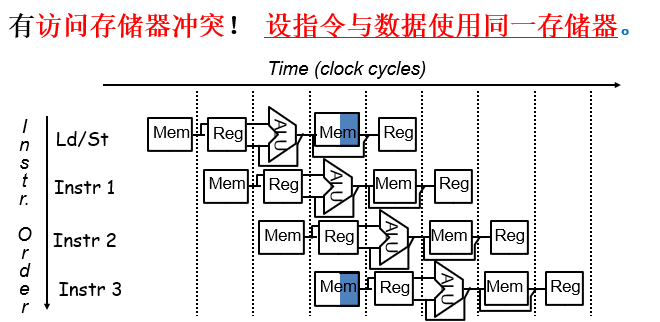
解决:使用分开的指令cache和数据cache
图示:
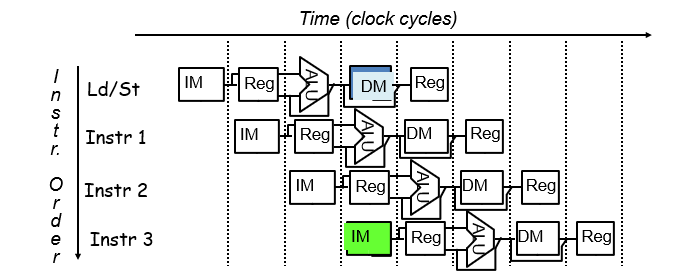
注意:如果时钟周期不变,流水线存储系统的带宽必须是非流水线的5倍
4.4.2 寄存器冲突
图示:
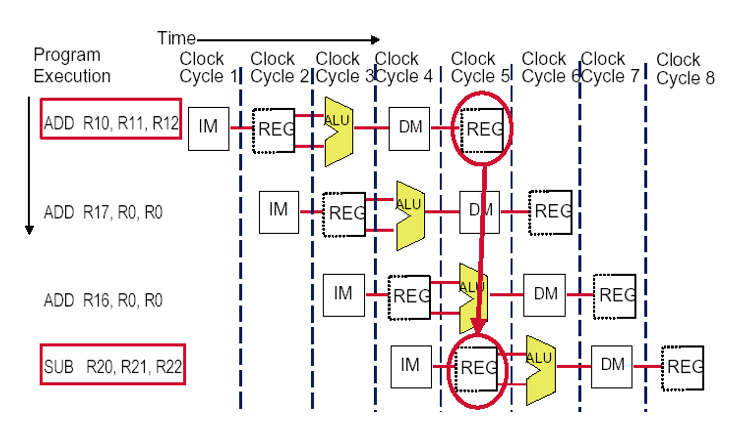
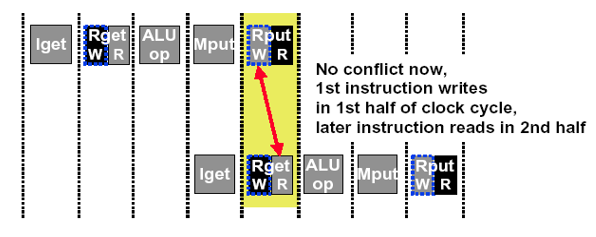
解决:重新设计寄存器堆资源
允许在一个时钟周期WB段先写,ID段后读
每个时钟周期完成2个读和一个写
需要提供两个读端口和一个写端口
当写和读同一个寄存器会发生数据冒险(Data hazard)
4.4.3 更新PC时冲突
每个时钟周期必须增量PC并存储到PC
遇到转移指令时可能会改变PC的值,可能会产生控制冒险(Control hazard)
5. 流水线的基本性能
- 增大了吞吐量(单位时间完成指令条数)
- 每一条指令的执行时间没有加快
- 延迟:附加的控制增加了开销
- 不平衡:流水线各段时间以最慢的为准
- 附加开销:流水线寄存器
- 流水线冒险:串行机器不会产生冒险
- 填充和排空:会减小加速比
流水线的主要障碍-流水线冒险(相关)
1. 冒险分类与有停顿流水线性能
1.1 冒险分类:
- 结构冒险:指令重叠执行时,发生硬件资源冲突
- 数据冒险:几条指令重叠执行时,后面指令依赖前面指令的结果却没有准备好(没有计算或存储)
- 控制冒险:发生在流水线执行转移指令时,在进入ID段时,转移条件和转移目标地址不能按时提供给IF段取下一条指令
冒险出现时:避免流水线上有冒险的指令执行下一个流水段
冒险总是可以用停顿(流水线气泡/气泡)解决:停顿时,其后的所有指令被停顿,指令之前的指令继续执行,没有新的指令被取到流水线
图示:
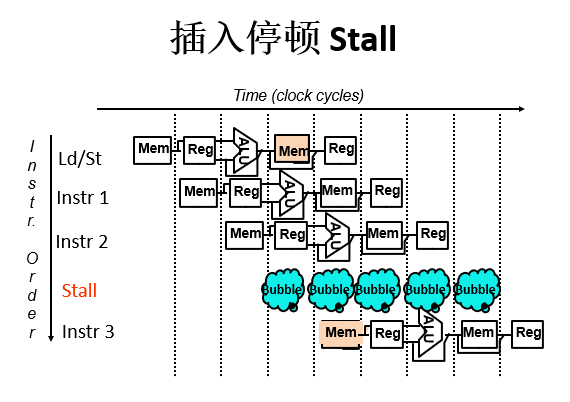
1.2 有停顿的流水线性能
加速比公式:

流水线CPI=理想CPI(≈1)+平均每条指令的停顿周期数
忽略流水线时钟周期的额外开销,并假设流水段是平衡的,则:非流水线时钟周期=流水线时钟周期
最终得:

2. 结构冒险:流水段竞争
2.1 定义
发生在同一时钟周期,2条或多条指令想要使用同一硬件资源
2.2 出现情况
- 多重访问寄存器堆
- 多重访问存储器
- 没有或没有充分流水功能部件
2.3 解决
寄存器堆的多重访问
图示:
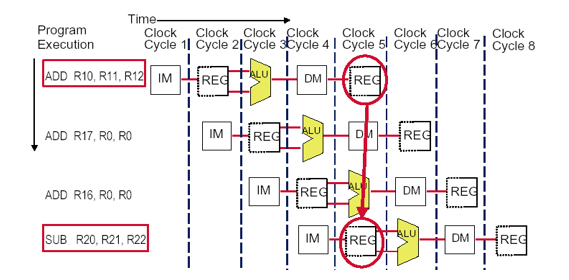
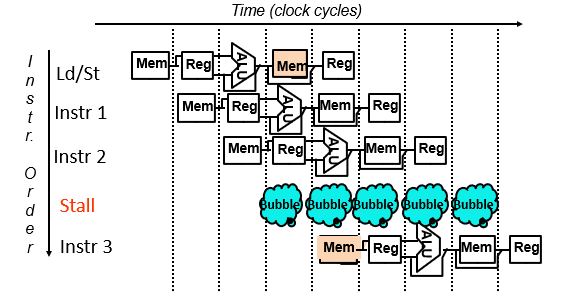
方法1.:简单插入一个停顿,将降低加速比
方法2:在一个时钟周期WB段先写,ID段后读
多重访问单端口存储器
图示:
方法1:插入停顿
方法2:提供另一个存储器端口
方法3:分开指令存储器和数据存储器
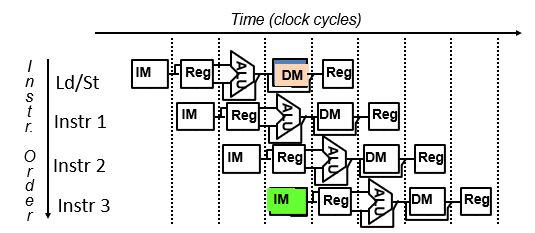
方法4:使用指令缓冲器
没有完全流水化的功能部件
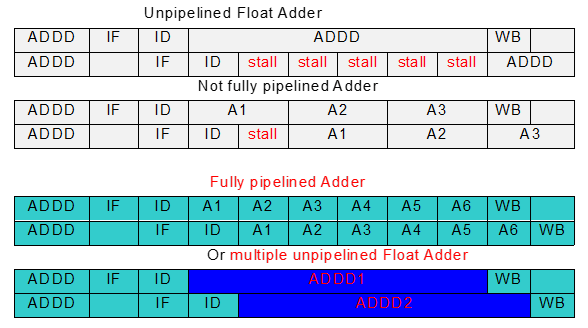
2.4 认识
结构冒险是被允许的,为了减少成本、减少部件延迟
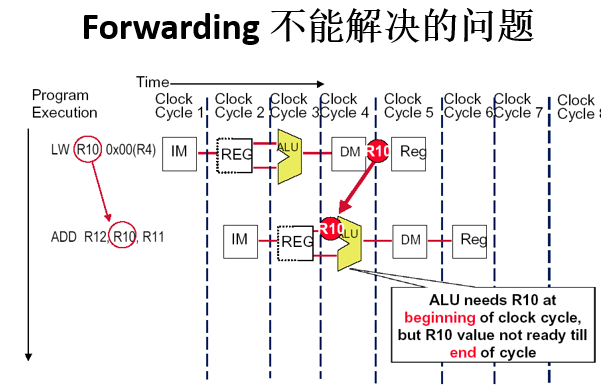
3. 数据冒险
3.1 定义
由于流水线上指令重叠执行,改变了原来串行执行的读/写操作数顺序,使得后面依赖前面指令结果的指令得不到准备好的数据
3.2 解决
不要让指令在数据冒险时重叠执行
3.3 实施
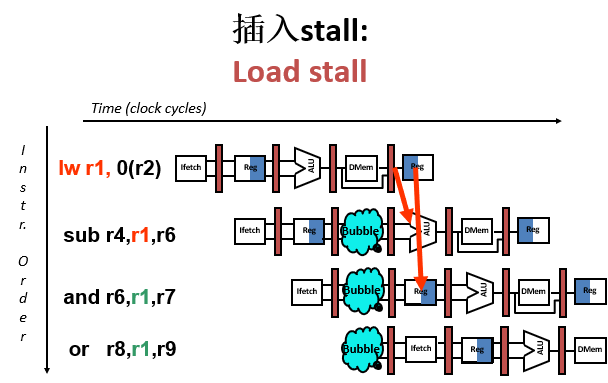
流水线停顿
软件:
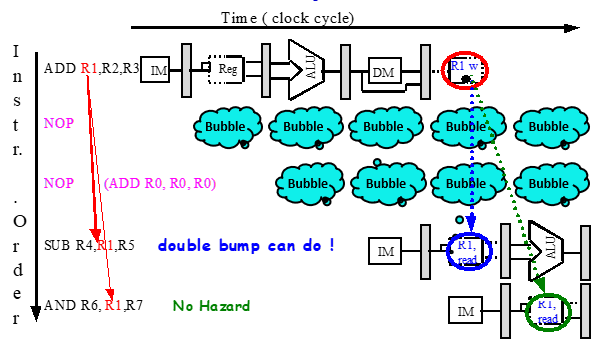
硬件:
增加硬件互锁(Interlock)
增加额外硬件检测需要停顿的情况
增加额外硬件放“气泡”(暂停)到流水线
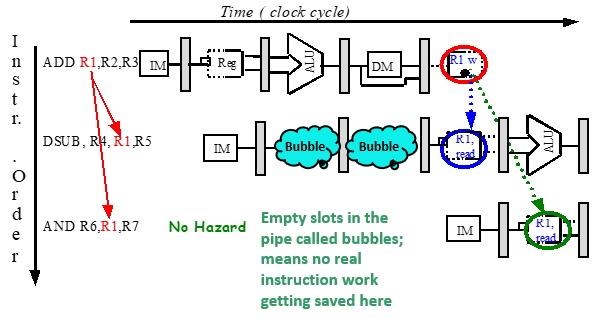
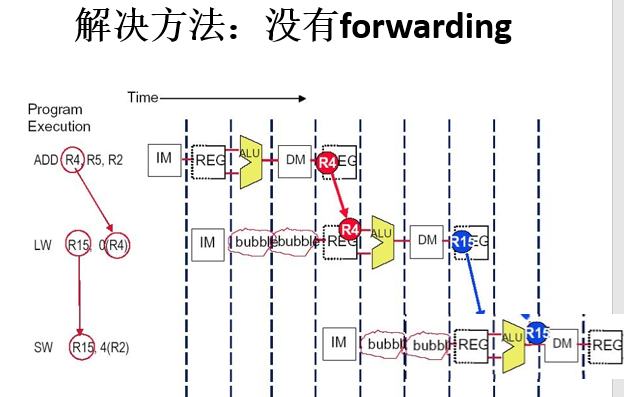
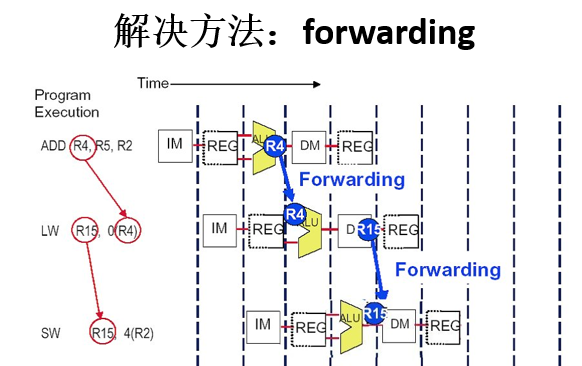
3.4 Forwarding(前推、直通、转发、相关数据通路)
有数据冒险指令需要的结果可能已经计算出来,存放在流水线寄存器中,所以我们可以在数据通路中增加数据线(buses)传送这些结果,这些buses总是从后面的流水段连接到前面的流水段
图示:
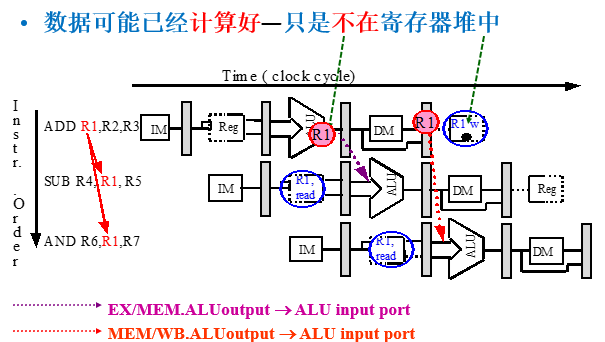
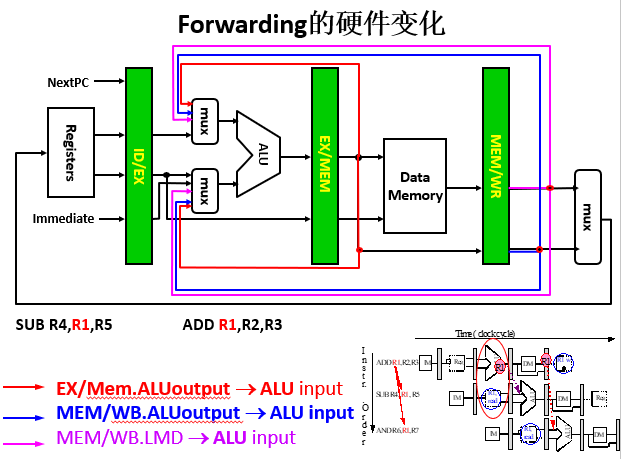
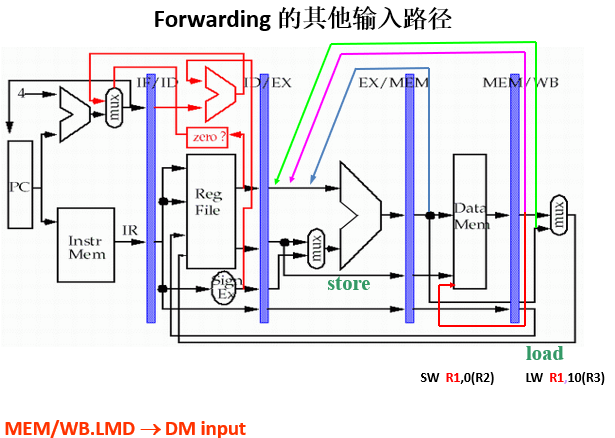
没有Forwarding和有Forwarding的比较: