编译原理第六章-词法分析
词法分析:编译程序对源程序进行分析和目标程序合成,最终生成目标程序
预处理子程序(预处理器)功能:
- 删除编辑用字符,如制表符、换页符等
- 删除注释
- 合并多个空白字符为单个空白字符
- 组合多个独立文件中的源程序
- 展开宏定义
- 条件编译的选择等
其中,2、3等也可以在词法分析的同时进行
1. 词法分析概述
扫描源程序的字符串,按照词法规则,识别出单词符号作为输出;对识别过程发现的词法错误(非法的字符、不正确的常量、程序括号等)进行处理
词法分析器只执行一次:
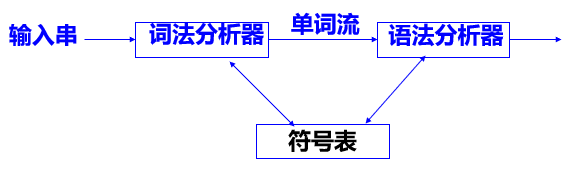
词法分析器执行多次:
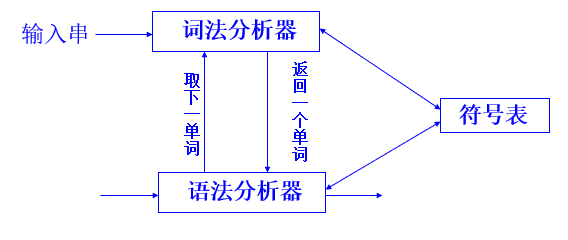
2. 词法分析器的输出形式
2.1 单词的种类
- 标识符:用来命名程序中的实体,如类型、变量、函数、过程、标号等
- 基本字(关键字):如if、while等
- 常量:各种类型的常量
- 运算符:如+、-、*、/等
- (分)界符:如;、{、}等
eg:

留意最后的换行符‘\n’也是界符
2.2 单词的输出形式
使用二元式表示:

3. 单词类别的划分
3.1 单词的编码随类别不同而不同
- 基本字、运算符、界符的数目是确定的,每个单词与它的类别码为一一对应的关系,即一字一码,故而它们的第二元可以空缺
- 标识符通归一类
- 常量可按整型、实型、字符型、布尔型等分类
eg:
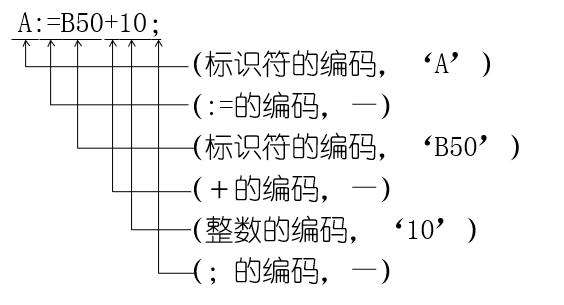
通常用常数在常量表(标识符在符号表)中的位置(编号)作为它们的属性值

3.2 单词的识别方法
标识符和关键字的识别
需要超前搜索(多读一个字符以确认上一个结束)
读到 非 字母数字停止
常数的识别
部分常量需要超前搜索
运算符的识别
1个或多个符号构成
需要超前搜索
界符的识别
不需要超前搜索
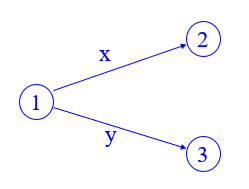
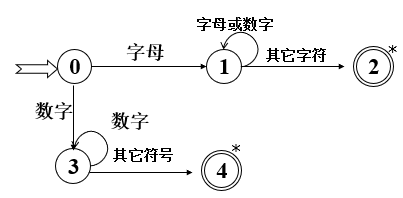
4. 状态转换图
状态转换图是设计词法分析器的有效工具
状态图特点:
- 有限的有向图
- 有向边上标记字符
- 唯一初态
- 若干终态(至少一个)
图示:
eg:
识别标识符和数字串的状态转换图:
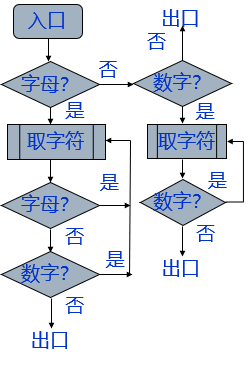
它的流程图:
5. 词法分析器的设计
5.1 单词符号
标识符:begin、end、integer、if、then、else、function、read、write
无符号整型常量
运算符:-、*、<、<=、<>、=、>、>=、:=
分界符:;、(、)、
5.2 状态转换图
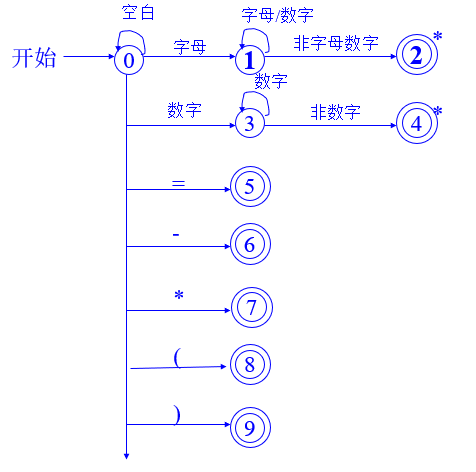
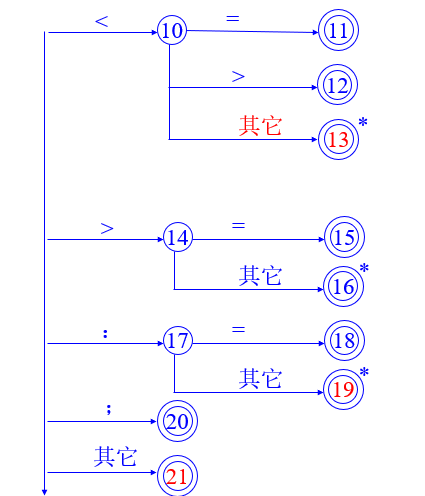
注意:有*标记的状态需要回退一个字符
5.3 一个示意算法
以下是将会用到的变量、函数和过程
cha
字符变量,存放最新读入的字符
token
字符数组,存放已读入的字符序列
getchar()
读入字符的过程,从输入字符串(源程序文件)中读入一个字符到变量cha中
getnbc()
读入非空白字符的函数
concat()
连接字符的过程,把cha中的字符连接到token数组的末尾
letter()
判断字符是否为字母的函数,若cha中的字符是字母,返回true,否则返回false
digit()
判断字符是否为数字的函数,同上
retract()
回退字符的过程,将刚读入cha中的字符回退到输入字符串中,并将cha的值置为空白
实现方法:不需要真正回退,可以设置标记位。
reserve()
处理保留字的函数,对存放在token中的字符串差保留字表,查到返回该保留字的类别编码,否则返回0(假定0不是任何单词符号的类别编码)
bulidlist()
对token中的字符串查符号表,查到返回位置编号,否则将该串存入符号表,并返回它在符号表中的位置编号
dtb()
将token中的数字串(字符串)转换成二进制,存入常数表中,并返回它在符号表中的位置编号。若已经存在,则直接返回它在表中的编号
return(num,value)
返回二元式函数,num为单词类别编码,value是单词在符号表中的位置编号,或是它在常数表中的位置编号,或是0
error()
处理出现词法错误的过程。有一类词法错误可以在词法分析时发现,如出现字母表以外的非法字符。不和规则的常数等。但有一类词法错误例如if写成fi,词法分析会将fi当标识符处理,length中多了个空格,词法分析会将le和ngth当作两个标识符处理,这类错误要推迟到语法分析时才能发现,当作语法错误处理
伪代码:
1 | Word_Struct LexAnalyze() |
以上代码将词法分析器实现为一个函数LexAnalyze(),函数没执行一次,就会从输入字符串中识别出一个单词符号并按二元式形式返回。